Descriptions
This paper describes a hybrid symbolic natural language parser architecture with two
primary layers. The first layer is a chunker
, i.e., an analyzer that identifies basic
syntactic chunks such as basic noun phrases (e.g., the happy child
), and the second
layer combines the chunks.
The combination provides good performance because (a) chunking can be done more efficiently than more general parsing, using different techniques and (b) given larger chunks to combine, the subsequent phase has fewer alternatives to check. The latter also allows for a simple, effective, preference method for selecting "best" parses.
The chunker consists of the very fast XIP chunker software built at the Xerox Research
facility at Grenoble, France together with a chunker grammar (a collection of rules) for
English. Chunker rules are applied in sequence to build chunks, and, once constructed,
a chunk is undone only by some final fixup
rules applied at the end of the analysis.
Importantly for subsequent processing, the chunker allows lexical entries and chunks to
be tagged with various features (e.g., this is a place
). The XIP chunker distribution used
in RH included an initial chunker grammar for English, which was extensively modified
and extended as part of the RH parser development.
The second layer of RH is an ATN-like parser, augmented by many constraints and preference tests, which combines the chunks to form larger units and then full syntactic parses for sentences. The innovative, but simple, preference scoring system (see preference-system-specific paper) utilizes both syntactic and semantic criteria to select the best syntactic parse. At the time of publication, the parser was as fast or faster than most other published parsers, and accuracy was close, and was continuing to improve.
This paper details the second layer of the RH parser, which combines basic chunks
supplied by the first, chunker
layer (see summary paper), and focuses on the preference
scoring aspect. Unlike earlier preference schemes, the scoring is very simple. During the
parse, each new attachment (e.g., the attachment of a PP within a VP) is given a score,
which is either -1 (dispreferred), 0 (no preference), or +1(preferred), based on both
syntactic and semantic grounds. The best parse is that with the highest cumulative score
(with low attachment preferred for equally high scoring final parses). As the parse
progresses, similar partial parses with lower scores over the same extents are discarded, a
critical contributor to parser efficiency.
The simplicity of the scoring system is enabled at least in part by the fact that its job is to assign scores to combinations of relatively long sequences with clearly defined properties, so the effects of assigning scores are more easily predictable, and less fine- tuning is needed. Also, in testing and improving the parser, errors attributable to scoring are easily traced to their source.
The TextTree representation was developed during the RH parser project to expedite parser development. TextTrees are formed by converting parser output trees into unlabeled indented strings with minimal bracketing. An example TextTree is
They
must have
a clear delineation
of
[roles,
missions,
and
authority].
Reading a TextTree for a correct parse is similar to reading ordinary text, but reading a TextTree for an incorrect parse is jarring. This property allows a file of TextTrees to be read rapidly to review the results of parsing a long document, in order to find (and then analyze) problem areas. See paper for examples and for the TextTree construction method.
TextTrees are constructed by a parser-independent mechanism that accepts, as input, parser output trees which are expressed in a standard form, but with grammar-specific category labels. The formatting is guided by user-specified rules, one per category, expressed as <category, directive> pairs, e.g., <ROOT, Align>
The combination of a symbolic natural language grammar and the software that interprets it can be viewed as a component of an application or system in the same way as the combination of a program in some language (e.g., JAVA) and its interpreter can be viewed as such a component. Thus, just as it is appropriate to look at a programming language and its processor from the point of view of amenability to testing and debugging, it is reasonable to do the same with respect to a grammar formalism and its interpreter.
This paper describes tools associated with the RH (Retro-Hybrid) parser that facilitate grammar testing and debugging and are, to varying extents, more broadly applicable. The paper also suggests a new approach to improving parser efficiency using constrained inputs, based in part on one of the RH debugging tools.
The MailContent project was inspired by direct personal experience. Circa 1999 the author was asked to participate in a number of standards groups having long histories and accompanying large email-based forums; too large to easily select the threads and subthreads contained the most important background and/or immediately pertinent information. So, shortly thereafter, she began to consider alternative presentation mechanisms for email forums.
Many of the major results are described in this paper. They include a number of ways of presenting overall forum content, and new thread visualizations. Overall forum content is provided via several types of enhanced subject listings, giving an immediate appreciation of the most important threads and subject matter.
The new thread visualizations consist of narrow trees
and treetables
. Narrow trees
address
the problem that the standard representation of long message/response sequences, where responses are serially
indented, lead to thread representations extending far off the right side of a window. This problem is avoided
by a different, but clear set of conventions... see paper for method and examples.
Treetables
provide an immediate appreciation of the structure of a discussion, e.g.,
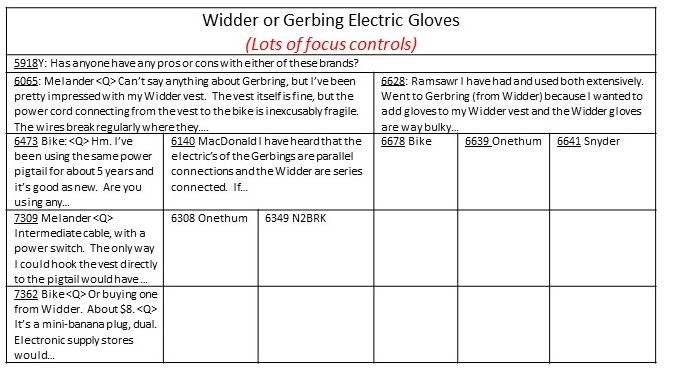
(Note: For the various types of displays, message abbreviations are obtained using finite-state-based analyses of message structure to isolate substantive content from other material such as quoted passages, greetings, etc. Some details are described in related patents by the author.)
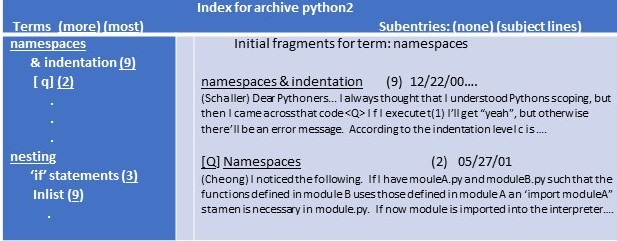
While most facilities of the MailContent project relate to the presentation of individual threads, this paper discusses a more global aspect: the formation of table-of-content-like information for full email corpora. This is achieved by grouping threads appearing to have similar subject matter. In the method used, subject lines are first scanned to select candidate subjects, specifically terms not occurring in a list of the 5000 or so most frequent words in the language. The candidate subjects are then ranked based on their relative importance in the archive, which is influenced by the number of thread subjects in which they occur, and by the lengths of those threads. A partial example index obtained from a python-related archive is:
This paper describes the method used in the MailContent project to obtain thread summaries, approximately divided into subtopics. Messages are first grouped into connected subtrees by forming a word vector for each message, and then clustering the vectors. (A critical aspect of message vector formation is the adjustment of messages to avoid distortions in lexical distance due to differences in quoting style.)
Then two types of summaries (respectively developed by the two authors) are extracted for each cluster: a shorter overview and a longer treatment. Both types of summary use parameters such as semantic centrality and readability. For example:
This paper describes an adaptation of treetables for building alternate versions of short narratives. On returning from a sabbatical and seeing the email-forum-oriented treetables for the first time, Dr. Zellweger realized that a similar approach might be preferable to an earlier one for story building and visualization. This paper describes that earlier method, and then the treetable-related adaptation.
In the adaptation, the basic treetable design is modified. In both kinds of treetables, each column represents a single path from the root to the end of a branch. In the original treetables, preservation and representation of structure is of major importance, so elements at the same depth are aligned horizontally, and their content abbreviated if necessary (and viewable in full via controls). However, in the "fluid hypertext" approach, each column represents one version of a story, and includes all text of that version. The adaptation is named “unaligned treetables” because, to allow complete stories to be viewed conveniently, contributions at the same depth but along different branches are not “aligned” horizontally. Suitable controls are provided to explore the displays, for example to focus on specific sequences.
The Xerox Linguistics Environment (XLE) succeeded the initial Common Lisp implementation of the LFG formalism, and contained many changes. This paper focuses on facilities for specifying lexical preprocessing and the lexicon proper.
“Lexical preprocessing” includes both tokenization, which splits input texts into words and punctuation, and also morphological analysis, which divides words into components. For example, “books” might have the two analyses: “book +Npl” and “book + VSg +VPres”.
In the Lisp implementation, lexical preprocessing was specified by sets of explicit rules, along with the grammar rules and the lexicon proper, and alternatives could be combined via specification called a “configuration”. In XLE, configurations instead provided for the use of multiple external components for lexical preprocessing. In the result, morphological processing might be specified as, e.g.,
USEFIRST serves to provide corrections to large scale analyzers. It specifies that, for a particular word, only the results of the first listed analyzer to find any analysis for that word are to be used. “USEALL” extends analyses to add words or entire topics.
Specification of the lexicon itself was augmented to facilitate the assembly and correction of large LFG lexicons. A full LFG lexicon entry for a word, e.g, “down”, might look like:
It has two subentries, specifying “down” as either a P_BASE or an ADV_BASE (@PREP and @DIRADV are macro-like labels for collections of properties). Originally, lexicon configurations could only add or replace full entries. (e.g., the entire entry for “down”). The replacement provided fine-grained, flexible modifications specified at the subentry level. This was especially necessary for verbs, where different subentries, implying different meanings and dependent types, are needed in many languages.
This paper was first written as a term paper for an audited Stanford graduate course in computational linguistics. It describes how LFG grammars might be extended to cope with clitic motion phenomena. In just a little more detail. In some languages, some very small unstressed words, like auxiliary verbs and prepositions, can occur in different places in a sentence, based on what are considered by some to be “prosodic rules” (~ rules based on auditory considerations) rather than grammar rules. There are many studies, relating to different languages, of these possibly prosodic rules.
This paper proposes several alternative means of incorporating provisions for prosodically-positioned clitics into LFG, a formal syntactic grammar, and dealing with those provisions in parsing and generating texts using the resulting grammar.
Machine translation (MT) research in the 1980s focused on symbolic processing and thus issues of rules and representations. The LASC/MT project, at IBM’s Los Angeles Scientific Center (c,.1987-1990) gradually arrived at an interesting but ambitious design. Unfortunately, the center closed before implementation could proceed.
Because much of the expected MT system operation was largely documented in technical reports and IBM-sponsored or internal conference papers, it is briefly outlined here. The evolved system design consisted of:
look at ...vs.
look forward to...)
The grammar formalism, which is the focus of this paper, was bidirectional, i.e., intended for use in both
parsing and generation. It is described as a collection of modifications to the slot grammar
developed by
Michael McCord of IBM Research. "Slot-grammar" nicely separates dominance information (e.g., a verb dominates
its object) from precedence information (e.g., English active verbs generally precede their objects). The
modifications further separated the two kinds of information, and re-expressed some grammatical
information as features, for example, that a reference is definite
.
These modifications were intended to allow the precedence data for an input to be ignored after parsing. Then the dominance information, after lexically-based transformations, could be used as the dominance part of the target language representation. The paper describes the modifications in detail, including the use of “zones” for detecting and expressing discourse-oriented features.
To continue with the system design outline: After parsing, the transfer
aspect of the system
was carried out via the single concept lexicon
mentioned above. Each entry in a unilingual lexicon
would have an associated entry in the concept lexicon, constructed or connected when the unilingual
lexicon entry was created. The concept lexicon entry, in turn, might related to the target lexicon in one of the following ways:
knowmaps to several Romance concepts, or
acrossare not found in some languages. In such cases, the concept would have associated phrasal restructuring rules.
(Two notes. First, the concept lexicon was also the suitable place
for ontological information, i.e., is-a
information, useful in (unilingual) disambiguation.
Also, the design underwent further refinement after a study of Chinese; see description of paper An Approach to Paraphrase in MT Systems Based on a Study
of Chinese Verbs
further below.)
This short paper focuses on the advantages of ID/LP
grammars for parsing and generation.
In ID/LP grammars, immediate dominance
relationships (e.g., a verb dominates its object) are
specified by different rules than linear precedence
(i.e., ordering) relationships.
The paper is overly laborious, examining some implications of using a non-ID/LP grammar for generation. However, in the overall design of the MT system, the use of an ID/LP grammar allowed the results of ID rules, modified by mostly word-triggered translation rules, to serve as generation input. For an overview of the MT project system design, see the description of the "Symmetric Slot Grammar" paper, above.
(Note: This paper was accepted to the above conference, but we later received notice that the conference, scheduled to take place in Changsha a few months after Tiananmen Square, had been cancelled. There are some web references to a proceedings, and I am trying to find out more about that. In the meantime, I have stored a copy of the paper locally)
This paper motivates and describes some changes needed to the initial MT system design developed at IBM’s Los Angeles Scientific Center, based on a study of Chinese verbs.
The system design consisted of (a) a grammar formalism intended for bi-directional use
(i.e., for parsing and generation), (b) a unilingual lexicon for each language to be handled by an
instance of the system, and (c) a common lexicon
spanning those languages.
During translation, parsing produced a dependency representation, where each head word was connected
to its dependent content words and many grammatical words
(e.g., determiners) and affixes
(e.g. for plurals) were represented by features.
A word was identified by a reference to its unilingual lexicon entry, which, in turn, was linked to an
entry in the common lexicon
for the MT system instance. And, in the reverse direction,
each entry in the common lexicon was linked to all the unilingual entries to which it directly translated,
possibly with the addition of some unilingually required material.
After parsing, the more substantive aspects of transfer consisted of modifications to the parser output made if
knowin English often must be further disambiguated) and/or
run across ...-->
traverser ... a courant)
This design was developed primarily in relation to Romance languages, for which the above provisions seemed adequate. Then a study of its utility for translating to and from Chinese indicated the need for a better approach to structural changes. The paper describes and analyzes many examples of translating Chinese motion verbs, and then outlines a direction for a systematic treatment of the required structural changes using a feature-based typology.
This paper describes a means of disambiguating parsing ambiguities. The approach is an ambitious one,
aiming to simultaneously disambiguate both structural and sense ambiguities. Structural ambiguities are
ones of head-dependent relationships, for example, in He gave a present to Mary
, to Mary
is a dependent of the phrasal head give
, while in. He saw a letter to Mary
, to Mary
is a dependent of letter
. Sense ambiguities are ones of meaning, for example, letter
in the foregoing example can be a missive or a member of an alphabet.
Unfortunately, there can be a huge number of combinations of possibilities. Even in the short sentence
He shot some bucks with a rifle
, shot
can mean fired a weapon
or wasted
,
bucks
can be animals or dollars, and with
can specify an instrument (of shooting)
or an accompanier (of either the shooter or the things shot).
The paper shows how this potentially combinatorial explosion can addressed using a variant of the A*
search optimization method. The possible head-dependent pairings are first organized into choice point
sets. Each such set represents a dependent word, and contains pairs of its senses with senses of its
possible heads. For example, a pair within the with
set would be,
< with = instrument, shoot = waste>. The method requires that all these pairs
be given a score. For example, expected head-dependent pairs like to… give
receives a high score
because give
expects a modifier to
.
The choice point sets are conceptually organized into a tree whose levels represent the choice points, and choice points with the largest differences in scores are placed highest in the tree. Then a variety of A* (see paper for details) can be used to optimize the number of tree nodes actually examined.
Later work by the author (see 2007 papers) suggests that structural ambiguities can be handled with less sense information, and that many sense ambiguities may be left to be dealt with depending on need.
The Integrated Development Environment project at IBM’s Los Angeles Scientific Center was concerned with two related types of integration: vertical integration of tools for requirements gathering, specification, and implementation, and horizontal integration of specification and programming languages with their data references.
This paper is primarily concerned with vertical integration. In the mid-1970s data processing was increasingly supporting many business activities, and thus there were many software-engineering related research efforts devoted to understanding how to collect and combine data and processing requirements, how to express designs, and how to expedite implementation. This gave rise to a multiplicity of unrelated tools that inhibited their utility.
The paper motivates and suggests a direction for increased attention to integration of these tools, including:
- The use of a coherent system repository for system description data at all levels.
- The use of an expressive data model that shares characteristics of the E/R
and relational models for that repository and for application data as well.
- The use of closely related design documentation languages and programming languages,
thus allowing the use of similar concepts and providing inter-level comparability.
- The use of partial and full application generator capabilities
(For more on the intended data model and language see “The Data Model of IDE”)
The Integrated Development Environment project at IBM’s Los Angeles Scientific Center was concerned with the complexity of enterprise system specification and implementation. One cause of the complexity was seen to be the use of different data models for (a) “conceptual” models of enterprise data, (b) their implementation in data bases, and (c) program-local data.
This paper describes a data model that shares characteristics of the E/R and relational models and was intended for all the above purposes. The paper also discusses aspects of the programming language, PL/IDE, so as to demonstrate the adequacy, convenience, and power of the model. The data model is ultimately based on work by the author circa 1976, with William Kent, on an ad-tech IBM project related to data dictionaries. The programming language is more fully described in an IBM Scientific Center Report G32-27094, June 1980, which may become available online.
In a nutshell, in PL/IDE both program-local and data base data are organized into scalars, tuples, and sets of scalars or tuples. Scalars and the elements of tuples must be elements of either "built-in" sets (e.g., integers, reals, strings...) or other, more dynamically constructed, ones.
For concreteness, some aspects of the language, as it relates to data, are illustrated here. For example,
for data access, given a set "Course",
containing tuples such as <"Math", 404>, with tuple elements from the sets "Subject"
and "integer",
and a set "Lecturer" of tuples such as < <"Math", 404>, "J. Smith">
with elements from the sets "Course", and "Person":
- The expressions Lecturer (<"Math",404>) and
Lecturer (<" Math", 404>, ?) would be equivalent and equal to "J. Smith".
- Lecturer (?, "J. Smith">) would be the set of all courses for which
"J. Smith" is the lecturer.
Query and assignment forms are inspired by the non-data-base-related language SETL, by Jacob Schwartz.
As examples of assignment forms:
- Lecturer (< "History", 101>) = "W. Jones"
- Course += < "Biology", 200>
Iteration is over query-specified sets. Data base references are identical to local ones, except that the referenced data base names are prefixed to the set names, e.g., MyDB.Lecturer.
The paper also introduces additional aspects of the data model and related language, and compares the data model to other similar ones.
A brief note suggesting and illustrating the use of a "SELECT" statement (described) in place of nested IFs for reasons of readability and comprehensibility.