The previous chapter dealt with my work from roughly 1972 through early 1975. I began that chapter by saying:
For me, the next 11 years or so were a technical odyssey. The adventure started with learning something about the ways files and data bases were structured and accessed. It ended years later with defining a programming language that considered all kinds of data, program-local and persistent, as conceptually similar, accessible via the same kind of simple reference, possibly usable at many stages of systems design and implementation.
The next stage, this one, consisted of two years in which I collaborated on the design of a data model and an accessing language for that model, which took things part of the way towards the programming language mentioned above. The work for this stage took took place in the context of an effort concerned with developing a data dictionary. So in this chapter I'll talk about all those things and their relationship. (A data model is a way of conceptualizing information, generally for purposes of accessing it. The term is most often used in the context of data bases; much more about this later).
I'll start with discussing data dictionaries in general, and go on to the organizational background for the dictionary effort I was involved in. Then I'll move to the why and what of the data model and accessing language designed during that effort, which remained a work in progress. And then a bit about aftermaths.
So, to begin... about data dictionaries. The original, and still central purpose of a data dictionary is to provide an easily accessible repository of descriptions of the structures and content of a collection of persistent data. The key idea here is "accessible". Data dictionaries may also serve wider purposes as repositories for other information related to the data and to how it is used.
The need for data dictionaries emerged as data bases grew in scope, and so became more important to various parts of an organization, while, at the same time, the job of establishing data base structures, and even finding out about those structures, was usually quite tedious (even for people with the specialized skills needed).
Why? I'll call the structural information associated with a data base a "schema", since that is the name frequently used for that purpose. So one question was how schema information is best communicated to a data base management system. At the time (in the mid-1970s) there were a few obvious choices. One could use a specialized command language tailored to the particular data base management system. Or one could use one instance of the data base type, containing predefined structures, to create and modify definitions of the information to be stored in another instance, using the primarily record-by-record navigation methods used for available data bases. A third possibility was to camouflage some of the difficulties of the first two methods by using the very simple display interfaces available to assist in entering the necessary information. None of these choices were particularly attractive.
A third, less obvious possibility was to develop and use a more convenient type of data base to store the definitional material. In other words, one motivation for a data dictionary was to recognize that it was, itself, a collection of data, and to use a data model oriented toward ease of access. Such a choice could be less concerned with performance, because the content was expected to be limited in size and infrequently accessed.
But there were addional motivations for separate, more accessible repositories for data-base-related information. It was starting to be realized that there was more information about data bases that might be useful to retain and communicate beyond detailed structural definitions. For example, it would be useful to store more information about the meaning and intended use of the data, probably in text form. And, as a centralized repository, it might also contain programming language versions of data declarations, for use in other programs. And this, in turn, suggested a broader picture of potential data dictionary function. Not only did data base structure designs go through iterations, but they were deeply connected to the design of an entire enterprise software system. So one could start to consider a data dictionary as a design data base, containing not only the currently-in-force data definitions, but projected ones, and also information about existing and intended application usage, as well as overall system designs.
All the above influenced what we did during the dictionary project to be described here. But I'll start with the organizational setting, which also helps to make sense of what was done.
The dictionary project I worked on began during a time of change in IBM's data base development organizations. From 1972 through early 1975 most data-related development was focused on creating the data base subsystem of IBM's corporate wide FS (Future System) project [FS_1]. The novel technical approach taken in that subsystem, described in detail in an earlier chapter, permitted the same information to be viewed and accessed via different kinds of structures, including traditional linear files, hierarchic files, and networks. This was achieved by cascading mappings to a common underlying base. (However, some development groups probably continued to focus on improving traditional file access methods and the IMS hierarchic data base product.)
The FS project was cancelled in the spring of 1975, but some of the software work, including some data base work, continued for a while under the occasional title "ESPS" (maybe "Enterprise System Programming System"). At the same time, however, there were changes going on, and one area affected was that of the data dictionary. To back up a bit. The FS data base architecture had included a repository for data structure definitions and mappings, which was to be accessed via a programming language interface to one of its defined data base structure types. There were also some groups intended to provide more "usability" with respect to establishing data definitions, via "interactive" means, but without creating a separate repository. This restriction generated some pushback from people concerned with the problem, as well as from those involved with the interfaces between programs and data bases.
These reactions, probably further influenced by a paper by Peter Uhrowczik on the potential of data dictionaries [UHROW], led to the formation of a working group, in early 1974, to consider alternatives. As a possible result, a department was created to implement a separate dictionary. The technical leader of that department was Bob Griffith, who had some novel ideas about a data model that might be used for a dictionary, and about what an interface to such a dictionary would look like. Writeups of the design featured the idea that "attributes" were often expressed via membership in collections and subscollections, which resulted in an interface whose query language focused on intersections among collections.
Then, by mid-1975, there were at least three different IBM-related data dictionary efforts. How did that come about? Well, first, there was the above-mentioned department, at that point associated with the FS follow-on. Also, a dictionary was being built by some IBM customers for use with IMS and related data management facilities.
And the third effort? That's where my direct involvement with all this begins. (I had been indirectly involved in that I had worked in FS on usability aspects of data definition and strongly supported the need for an alternative dictionary.) Anyway, in mid-1975 I participated in a series of discussions about the kind of dictionary needed to deal with existing products like IMS, and possibly contemplated ones as well. These discussions resulted in the formation of a new department to develop such a dictionary.
Then, over the course of the next year, the situation had changed considerably. The customer-developed dictionary had been extended and released as an IBM product ("DB/DC Data Dictionary Version 1.0"). Meanwhile, the two in-house dictionary projects had been given revised, related goals. The older department, begun during FS but later under new management, was charged with producing a "first release" of a dictionary consisting of a "dictionary engine" and a basic interface. The newer department was charged with providing a higher level interface, to be called "NDL" ("new dictionary language"), which was to cascade to the first-release interface. I can only make an educated guess as to how this came about. Possibly the older department had already done some work on an implementation, but its originally planned external interface was not well-regarded.
I was concerned with the NDL language design, and, probably with others, produced an initial specification for a command language. My only documentation of that initial language is a listing giving a brief, incomplete formal syntax. The syntax reflects a data model which shared some properties with other models that were evolving at the time, in that it included three kinds of objects: entities, their attributes, and their relationships with other entities. (The most well known of such models was Peter Chen's "Entity/Relationship" model [CHEN_76]). The emergence of that view was natural given that existing structured approaches (i.e., traditional files, hierarchies, and networks) usually consisted of records representing entities and their attributes, with structural connections among records representing relationships with other entities. In our syntax, the specifiable operations included the addition, extraction, and updating of individual objects so, syntactically, it was a rather humdrum command language. However, it did provide the ability to define new types, so the dictionary was extensible.
Then, roughly in early 1976, there was an important personnel change, which led to a major technical change. Bill Kent, who had done considerable thinking about data models, and had been following and critiquing the documentation as it developed, joined the NDL department and had a major impact on my thinking and on the overall technical direction of the group. We made what might be considered a small modification to the data model, but it inspired a very different language. Much more about that model and language further on.
(Note: About approximate dates. My only record of that command language is a computer-generated listing with a generated print date of mid-1976. However, the content was undoubtedly developed much earlier. I'm certain of that because that early syntax was not incompatible with the planned "engine" underpinning; it even had provision for "collections". But by the early fall of 1976 it was clear that the model we were developing was not compatible with the "engine", and by the late fall a full blown, very different data model and associated language specification had been documented.)
To round off the organizational preliminaries... The manager of the NDL department was Roger Holliday, who was quite knowledgeable about, and interested in, both data base systems and programming languages, and did a good job of coordinating the work. This conveniently allowed people to focus on their specific areas of responsibility. A less useful aspect, for current purposes, was that I recall little about areas of the project other the one I worked on. Bill Kent and I were together responsible for the data model and (most of) the external interface language, and it is those areas which I will primarily discuss in what follows.
As far as the other people involved, I recall that they were all very capable (and friendly). Lynn Samuels had been a member of the IBM Hursley (England) project that built the PL/I optimizing compiler. In the dictionary project she was responsible for (iteratively) devising and checking how the language would be used for IMS and related definitions. Len Levy had worked in FS on interactive access to the data base. In the NDL project he was probably responsible for the display interfaces, and for contributions of related usability features to the language. Juanita Mah was considerably younger, and this was one of her first professional jobs. Nevertheless, she designed and documented a detailed approach to implementing the query ("selector") part of the revised language. Her approach was exemplary, especially in a development organization; she integrated and extended external research work, and provided ample, helpful examples.
And, so, onward to the second, improved NDL data model and its associated language. Starting with the question of what led us, and others, to consider alternative data models.
In an earlier chapter of this memoir, on the database area of the FS project, I sketched the most important data base types of the early 1970s:
Also, by 1975, the System-R project [CHAM_1] was well on its way in IBM Research. The project implemented a relational data base and designed and implemented the SQL accessing language [CHAM_2].
The appearance of the above data models led to discussions, in both academic and commercial contexts, of how they were, and should be, used to represent different kinds of information. Such discussions, then and later, led to critiques of the representational adequacy of the models. To partially motivate why people looked at alternative approaches, I'll sketch a few aspects of the critiques.
First, many/most introductory discussions about how to design a data base, according to any of the above types, tended to begin by suggesting that people should first identify the important "entities" about which data was to be maintained. Together with the "attributes" of those entities. And also the "relationships" (to other entities) in which they participated. And this sounded fine. It suggested that in any of the above approaches, data bases were primarily made up of records of different types, each type associated with a different kind of entity, and each record was distinguished by an unique identifier and had values for type-specific kinds of attributes. So in a corporate data base one might have "employee" records, each identified by an "employee-number", and each also containing information about the specific employee (name, age, etc.) Beyond "attributes", relationships among entities might be identified, such as "employee-department" relationships, and the relationships might have associated attributes.
But when people came to actually design their data bases, they noticed that their existing and contemplated record-keeping systems didn't exactly correspond to the above notions. One difference was that while people might instinctively assume that "entities" meant tangible things, like "employees", and "parts", that didn't cover the landscape. In fact, what businesses historically kept lots of information about were instead events: buying and selling transactions, manufacturing runs, calendar items. (In other words, possibly the most important things were records.) And it wasn't always clear what might be considered an "entity" (like an employee) and what an "attribute" (like the employee's spouse), or what difference it made... Etc.
One way in which relational data bases were attractive in this respect, at least to me, was that their design could be considered a form of systems engineering. While there might be some passing reference to "entities", discussions rapidly got down to how to represent the data that was actually to be maintained. No fundamental distinction was made between "attributes" and "relationships". A data base administrator just decided how the data was to be reflected in the "tables" of the relational model. Each table consisted of one or more columns that together constituted a "key", which uniquely identified individual rows, and other columns contained values that were functionally dependent on (i.e., determined-by) the key.
But then one could question the relational approach as well. One problem was that it was often far from clear what was represented by the non-key column names, which sometimes seemed to express their relationship with the key (e.g., a "Part" relation might have a column labeled "current_inventory") and sometimes the domain from which the values were drawn (like "amount").
Another questionable aspect (of the relational approach) was that it continued the assumption that "attributes" belonged in non-key fields. But that didn't work when an object could have multiple values of the same attribute-like property. For example, if an "employee" could have multiple "skills". In such cases, the relationship had to be represented by a separate table with a compound key, like the paired columns "employee" and "skill".
And then people started to question why all things related to a key by 1-to-1 or n-to-1 relationships should be placed in the same table in the first place. Because the tables could be considered conceptual.
The above considerations and similar ones occupied many hours of conversation between Bill Kent and myself. One result of the discussions was an important paper by Bill critiquing record-oriented models, including the relational model. The paper was first issued as an IBM technical report [KENT_1] and a revised version, "Limitations of Record-Oriented Information Models" was externally published later [KENT_2]. I didn't write papers at that stage in my career, but Bill did give me appropriate credit; the acknowledgement section of the paper reads:
Many people made valuable comments on earlier versions of this paper, including Chris Date, Bob Engles, Bob Griffith, Roger Holliday, Lucy Lee, and especially Paula Newman, who suggested some of the ideas(emphasis mine).
That paper was one of Bill's many written works, published and unpublished. They included both technical papers relating to his assignments at IBM and later at Hewlett-Packard, and less technical material. (He once mentioned that he was never certain he understood some idea he came up with until he wrote it down.) Much of the material is available at Bill's website (which is still being maintained posthumously). His most well-known work may be "Data and Reality" [KENT_3], which entertainingly explores relationships between the "real world" and its portrayal in stored data. First published in 1978, it has since gone through two more editions, the most recent in 2012.
Overlapping the conceptual/philosophical discussions was the design of a data model with fewer of the identified drawbacks. I vividly recall talking with Bill one day in an office classroom, and getting up and drawing on the board a simple diagram that looked like this:
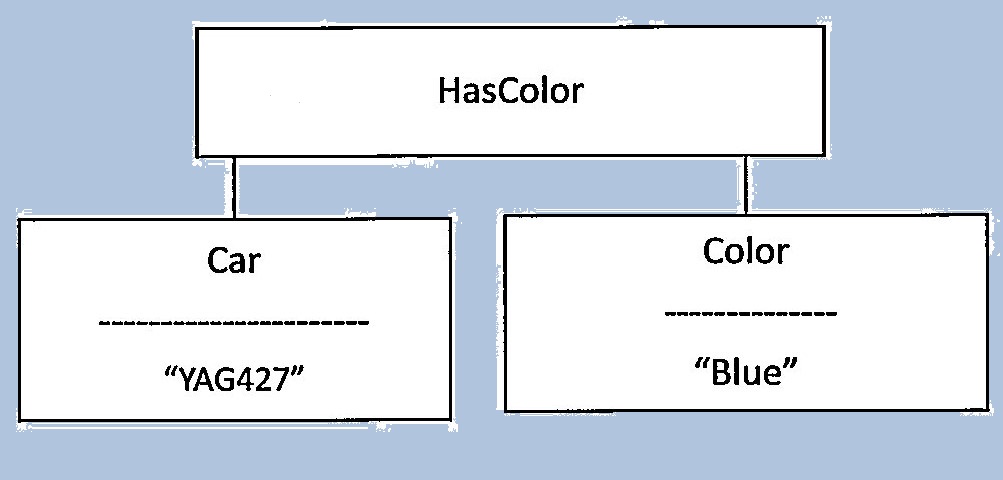
(at the time I owned a blue Dodge Dart). And Bill responded by more or less agreeing: "...yes, something like that." While the structure might seem to be implied by the various critiques, it wasn't as obvious to us at the time. In the model, a data base was considered to be made up of three kinds of objects: "things", "strings" (used to identify things), and "relationships". Relationship participants were ordered, so in the "HasColor" relationship depicted, the first participant was a "Car" and the second a "Color".
Thing instances were identified by a type (here a "Car") and a name string (here a license number). Relationship instances were identified by a type and their participants. Both things and relationships were capable of participating in relationships. Also, relationships could be of degree greater than 2. Strings had built-in subclasses, like "integer" which could be further constrained. So, in effect, the model decomposed the relational tables into individual associations, and clearly types of associations from the types of things being associated. And, unlike some other models, no distinction was made between "attribute" associations and "relationship" associations.
The data dictionary was always intended to be easily extensible, not just to support new kinds of file and data base descriptors, but other kinds of information of interest to individual users. To allow this, new "thing", "relationship", and "string" types could be introduced. New "thing" types were established as having the type TYPE, a type name, and the class of string used to identify things of the type. Similarly, new types of relationships were specified as also having the type TYPE, a type name, a specified number of "roles", and indications of the types of objects that could participate in the different "roles". Binary relationships were further characterized as whether 1-to-n or n-to-1 or m-to-n.
Note: We also spent a large amount of time worrying about vaguely theoretical "origin" questions such as what kind of object a name was, and how that came to be defined, but I'm not able to reconstruct those discussions.
As suggested earlier, our work was part of a simultaneous explosion of studies examining kinds of data meanings and/or possible ways of expressing them in data models. This development stemmed from a number of factors, probably including the expanded use of data bases, the increased variety of data base software offerings, and the focus, in the relational model, on "normalization", which directed attention to the different kinds of relationships embedded in data bases. The published, 1979 version of Bill's ""Limitations ..." paper [KENT_2] includes discussion of the roughly simultaneous work in data models, concluding with a listing of models that were somewhat related to ours:
Binary relation (or “elementary fact”) models are generally more successful in coping with the modeling problems, though none have done so completely. Such models are more directly based on semantic concepts, .e.g., entities and the network of relationships among them, rather than on recordlike structures. The model described by Biller and Neuhold [5] is excellent in this respect. Other models along these lines include the works (referenced below) of Abrial, Bracchi, Falkenberg, Griffith, Hall, Roussopoulos, Schmid, Senko, and Sowa.(NB:"referenced below" refers to the reference section of [KENT_2])
A few comments on the above excerpt.
First, it suggests a slight difference in focus between Bill and myself, with Bill somewhat more interested in the kinds of meanings that might be maintained in a data base, and I more in convenience of design and accessing. Thus Bill contrasts models "based on semantic concepts" with those based on "recordlike structures". I would rather say that record-like structures can complicate the design and extension of data bases by requiring decisions about combining facts into fixed larger units. And there certainly were some early binary models which were not explicitly "semantic". An example is Feldman and Rovner's LEAP system [FELDMAN], which they describe as:
a version of ALGOL[27] extended to include associations, sets, and a number of auxiliary constructs.
Also, while the referenced efforts were similar, they were not identical. For example, some considerations underlying the Biller and Neuhold work seem unrealistic. They suggest that a data base should reflect how situations are referred to in natural language, by using "relationships" to reflect things expressed by verbs and the "objects being related" by nouns. But many kinds of business records (whether maintained by Sumerians on clay tablets or by Bob Cratchit in a ledger) don't directly reflect how people might express information. Because verbs describe happenings, and, often, the happenings of most concern to an enterprise have many properties that have to be documented, which is done more conveniently using nouns (often nominalizations) for the happenings. Which gets us back to the "transactions" mentioned above. Someone might say "Today Bob sold a tractor to John Smith", but that would be recorded in an accounting system as a "sales transaction", probably identified by a transaction number, and related to a date, time, buyer account number, salesperson-id, sale amount, method of payment, etc.
Note: Either way of expressing the information (by verbs or nouns) would not necessarily help to interpret queries not referencing the data exactly as defined via the model. Consider someone wanting to know "What did we charge for Caterpillars in January?" Whether the associated query was posed in natural language or a formal query language, either (a) the user would have to know how the information was represented in the database in order to formulate the question, or (b) a considerable number of rules would be needed to translate the implicit relationships implied by the query to the data as defined.
Finally, this may be as good a place as any to discuss Bob Griffith's orientation in a bit more detail. While this is a bit awkward, it is sort of necessary, because a conflict with his "dictionary engine" department erupted not long afterwards. One way to put it. Both Bob and Bill thought and wrote deeply about data; about what kinds of objects and associations were involved and how they were and/or might be modeled. But their writings projected distinctly different attitudes. Bill had an entertaining approach to the subject; for every alleged truism ever stated about data, he could find a counter-example (implicitly leading to a preference for models not making many structural distinctions based on assumed meanings). Bob, on the other hand, had a very sober, serious approach to writing about information, as might be seen in [GRIF_82], and he tended to become attached to some aspects of the subject, like the connection between attributes and collections mentioned earlier. Some of the flavor is suggested by the discussion in [GRIF_82] of one part of Bob's once well-known, but internal to IBM, manifesto:
Membership relationships are fundamental. This is discussed in more detail in [20, Chaps. 3,4]. Therein finite set theory is rederived exclusively in these terms, and the laws of logic are derived graphically from the set theory
(I strongly preferred Bill's approach to the subject.)
As mentioned earlier, specification of the NDL language remained a work in progress. But possibly an interesting one. We began the language design with a model that had some very nice properties, but defining a language to use the model as the structure of a working data base and, further, one intended to serve as a data dictionary, posed challenges that we had not initially foreseen. So, by the too-early end of the project, there were parts of the language we were happy with, and parts that required more work. (As a partial comparison and excuse: the SQL language for accessing relational data bases, which has been a standard for roughly 40 years, went through 2 versions and decades of further development [CHAM_2])
Note: I discuss the language in some detail here, rather than just give a reference, because there is no published version. We never tried to publish aspects of the language at the time because, in a development organization, such material would have been considered proprietary. And by the time we might have considered publication, we were in different locations doing different things.
A few more preliminaries. First, I'm fairly sure Bill and I did much of the work on the basic language, and that others in the department dealt with further add-ons such as limited procedural aspects and user-role-oriented adaptations which I'll mention later. And they probably were involved to some extent with other aspects; I just don't remember specifics. Also, what follows mostly reflects the language as of early 1977, for which I have considerable documentation; there were unresolved issues (some of which I'll mention) and possibly some further developments, for which I don't have records.
Ok. So in this section I'll deal with the core of the language, namely, mechanisms to reference objects, to retrieve them, and to update them. An aspect I'll temporarily ignore is variation in usage environments. Instead, I'll start with the language as might be used via simple interactions with a primitive display terminal; one that could accept single- or multi-line commands, and display multiple lines of text.
Just about anything anyone would want to do with respect to the data would involve "selectors", that is, object references. Selectors were rather simple, fairly self-explanatory (I think) forms that exploited the decomposed aspect of the model to allow targeting of one or more objects. Two forms were used: identifiers and predicates.
Full identifiers represented individual things and relationships. A full "thing" identifier consisted of a type followed by a name, e.g., Employee:'John Smith', while a full relationship identifier consisted of the type followed by identifiers of all its participants, e.g.,
EmpDept(Employee:'John Smith', Dept:5023)
Also, in a full relationship identifier, participant types could often be omitted, giving, for example, EmpDept('John Smith',5023). This was because definitions of relationship types indicated their alternative role combinations and, depending on the latter, for some relationship types, all role types were prespecified and, for others, the type of the first participant could imply the others.
Partial identifiers were used as elements of predicates to represent relationships in which one or more predicate variables participated, as exemplified below.
Predicates selected multiple objects. The forms used quantified variables (THE, ALL, SOME), logical operators, and nested predicates. They also included some built-in functions, expressed as relationships. As examples:
The above forms were close to a natural fall-out of the model, and I think they were successful. And they could be used as minimal operands to query and update commands, such as: "LIST <predicate-form>" and "ADD | DELETE <selector>,.."
One further note about selectors: Identifiers had equivalent predicate forms. A thing identifier "type1:name1", in predicate form would be
THE ?x WHERE HT(?x, type1) AND HN(?x, name1)
while relationship identifier "type2(type3:name3, type4:name4,...)" in predicate form would be
"THE ?y WHERE HT(?y,type2) AND ROLE1(?y,type3:name3) AND ROLE2...."
Commands, or at least some of them, required more intensive design work, and the results were not quite as straightforward. Why the difficulty? An important reason was that there was a tension between the decomposed data model and the natural tendency of people to consider data as being organized in larger groupings. This would be the case whether the data concerned an IMS data base or a regional planning project, but it was particularly important for data about data structures. For example, IMS data bases contained multiple logical data bases, each of which contained records, which contained fields, and each such object type had its own kinds of properties. On the bright side, however, (a) the problem was not as difficult for retrieval, and (b) for update, there would probably be a tendency for people to focus on one level at a time.
For retrieval, the LIST command syntax provided for formatting of the results of queries to indicate grouping. The basic results listed individual results in a column, but could indent the listing objects to which they were related.
Indentation was requested by parentheses, thus
might produce:
But note that the above does not explicitly name the connecting relationships. This was awkwardly provided for by the ability to label subordinate elements according to how they were related. Thus:
might produce:
Also, a more powerful "report" function, to be supported by procedural extensions to the language, was intended.
The update aspect of the language was not as direct. The simple "ADD" and "DELETE" commands mentioned earlier were actually shorthand forms for a full form "EST" (for "establish") statement. One version of the statement, used to just add things to the data base, was not bad. It was fairly intuitive and avoided the need for repetitive typing. For example, to define or extend the definition of a record type in some target data base, the following might be used:
EST Record:Employee (
CtnsField Field:EmpName, Field:HireDate )
This would add to the dictionary the following items, if they were not already present:
Record:Employee
CtnsField (Record:Employee, Field:EmpName)
CtnsField (Record:Employee, Field:HireDate)
And if you wanted to add information about the above "Fields" you might write:
EST Record:Employee (
CtnsField
Field:EmpName( ::InDomain Domain:PersonName),
Field:HireDate( ::InDomain Domain:Date))
which would also add properties to the individual fields, that is the relationships:
InDomain (Field:EmpName, Domain:PersonName)
InDomain (Field:HireDate, Domain:Date)
The "::" prefixed to "InDomain" was used to deal with the question of whether InDomain is a property of the CtnsField relationship or of the Field operand. In case of such ambiguity, it indicated that the material following the "::" was a property of the last item mentioned (i.e., the Field). Anything before the "::" would be a property of the relationship. (Note: there was a certain amount of discussion on details of this mechanism.)
So, for example, if you also wanted to indicate the positions of each field within the record you might write:
EST Record:Employee (
CtnsField
Field:EmpName(Pos:1 :: InDomain PersonName),
Field:HireDate(Pos:2 :: InDomain Date))
However. The above presentation of the EST statement itself included a "shorthand". The full specification of EST used prefixed codes to indicate the actions to be taken with respect to individual operands. The above, which had null prefixes, indicated that the information specified was to be added if not already present. The (painful?) note, below, gives the details of this system. However, as mentioned earlier, the complexity might not be of as much concern as it may appear, because it is likely that (a) additions to the dictionary probably would involve only one or two levels, and (b) deletions (except for bulk deletions) and replacements would probably involve few items
Note on EST prefixes: Each operand was potentially prefixed by one or two characters. The first character indicated what to do with the operand, specifically:+ add item
- delete matching item
/ (only for 1-to-1 and n-to-1 relationships; replace matching item with operand
* do nothing with matching operand (indicates path to follow)
The second prefix character was either null (absent) or "/". A null second character indicated that the current situation had to be "congruent" with the indicated operation. So for "+" (add) as the first character, the congruent situation was that the item did not already exist. For all other first characters (- / * ) the congruent situation was that the item did exist. The second character, if it existed, had to be "/", and indicated that a congruent situation was not necessary.
A completely null prefix was to be interpreted as "+/", i.e., "add if not already there", which explains the simplicity of the first example. The meaningful combinations seemed to be:+ add, matching doesn't exist
+/ add if not already there
* no action; must exist
- delete, must exist
-/ delete if exists
/ only for 1-to-1 or n-to-1 relationships. Requires an R(a,x) & replaces it
// like /, but doesn't require relationship existence & establishes or replaces it
In addition to the above core language facilities, some necessary or potentially useful extensions were identified. I'll discuss some of these below: (a) versioning, (b) text processing related provisions, and (c) qualified naming. The reasons for the extensions are given below along with some discussion of their content. These extensions were less-well-developed, and might best be considered "interesting ideas".
Beyond these, other extensions to the language included procedural extensions, to allow the implementation of more powerful data-definition-related functions in terms of the model and language concepts, and some usability provisions to adapt the language to different types of users and usage environments. I'll discuss these just briefly.
One additional definitional property, usually associated with "thing"s, was an optional version number, attached via an HV = HasVersion relationship. Versioning was useful for a data dictionary or, for that matter, any other kind of data base that might contain evolving designs, often reflected in changes to some part of a larger grouping. So an extension was provided to assist in the installation of new versions. Without going into much detail, adding a new version would generally involve two operations: (1) explicitly adding the new version of the object plus its revised properties using an EST command, and then (2) specifying new versions of related objects in an abbreviated fashion.
For example, assume that a thing "FIELD:DEPTNAME#1" had a SIZE of 10 characters, which had to be expanded. And assume that the field was found in a record RECORD:EMPNAME#1. The necessary changes might be obtained by the following:
This would create a new version of the containing RCD, with new associations mirroring its existing ones except for its association with "FIELD:DEPTNAME1". The mechanism by which this was accomplished involved additional definitional information with thing objects to control the effects of ADDVS (which operation included additional alternatives which I will not discuss here).
Instances of some (user-determined) relationship types could be related to integers via "HSEQ" (has sequence number) relationships. Such relationships were given special treatment by the language. The sequence numbers could be used for conveying arbitrary types of information, such as the order of fields within a described record. However, their primary intent was to aid in using the dictionary for storing multi-line text, to express such things as (a) more detailed descriptions of data base objects, (b) other kinds of specifications, and (c) multi-line NDL commands, command sequences, and procedures.
To illustrate the use of HSEQ relationships, consider a process of creating a program specification, beginning with the command:
ADD DOC:INV_SPEC (CTNSLINE(HSEQ 1 :: 'This specification describes the inventory program.'),
(HSEQ 2 :: 'The program does what an inventory program should do.')
Or, in accepted abbreviated form where the prefixed numbers were inferred to represent HSEQ relationships:
ADD DOC:INV_SPEC (CTNSLINE(1) 'This specification describes the inventory program.',
(2) 'The program does what an inventory program should do.'
The result could then be reviewed via an extended LIST command:
LIST WHERE HSEQ (CTNSLINE (DOC:INV_SPEC, ?x), ?y) BY ?y
which would produce:
1 'This specification describes the inventory program.',
2 'The program does what an inventory program should do.'
And the result could be edited to change the second line by:
EST DOC:INV_SPEC (CTNSLINE(2) 'The program does the right thing.'
To further assist in text handling, a built-in relationship "HASKW" (HasKeyWord) was identified for use in searching for string objects containing a specified substring.
The need for considering dictionary objects as divided into groups required provisions beyond the factored forms for retrieval and extension discussed earlier. The major additional difficulty with our "decomposed" model was that we had to make provision for representing different things which had to be given the same type and name. While this problem could arise in any descriptive data base, here the problem was immediate and obvious; we had to describe operational data bases where, for example, multiple record types could contain identically named, but unrelated, fields. So the following is, approximately, what we specified. There were important open questions, and I'm far from sure that we were on the right track.
To start simply, the "top" of the dictionary was indicated by "!", so that an unqualified name was "!.identifier" (or, where ! was not required, just "identifier", which could mean the same thing). But some thing types could be directly identified as creating initial qualifiers. This was done by ESTablishing a "DQ" relationship with "!", e.g., "DQ(!,TYPE:DB"). This would suffice where one level of qualification was all that was needed to automatically provide sufficient name uniqueness. For example, if "DB" was established as such a top-level qualifier type, then the creation of an object "!.DB:Main" would thereafter allow DB:Main to function as a qualifier, and a new record "!.DB:Main.REC:TopRcd" would be unique to DB:Main.
Qualifiers could be made implicit overs some range of inputs using a "SETC" (set convention) command, or SETC clause within a command. Thus if "!.DB:Main" were made the implicit primary qualifier (there were secondary qualifiers as well), a reference to ".REC:TopRcd" would be implicitly expanded to its fully qualified name.
However, and this is where it gets (more?) iffy... Notice that in the above example, the actual definition of the data base in question (!.DB:Main) was likely to include an explicit relationship with its contained records. Something like "Contains(DB:Main, REC:TopRcd)". For this reason, certain relationships could be defined as "qualification relationships", and this meant that the first members of such relationships (at least of a specified type, like DB) would also function as qualifiers for the second members. Thus if, as before, DB:Main were identified as a qualifier, and "Contains" relationships whose first role was of type "DB" were identified as a qualification relationships with respect to their second role objects, then the creation of the above relationship would also license the use of "!.DB:Main" as a qualifier, at least for its "contained" records. So how is this "iffy"? Well, among other things, I haven't told you how one would reference "REC:TopRcd" in order to create it within its qualifier. And this is just one of the unanswered questions about qualification (and other areas) at this point of my records. So I'll say it might be referenced as
EST Contains(DB:Main, ..REC:TopRCD)
just to get us out of this paragraph. But I just invented the ".." notation.
Beyond stand-alone commands, a limited collection of statement types were identified for use in building NDL procedures, so that necessary or useful dictionary-related functions could be built without appealing to some lower-level coding. I don't think I participated in the definition of these extensions, but have the impression that they would serve the intended purposes, which included:
Some versions of these procedures were to be built in, such as procedures for basic object validation, as well as a report procedure accepting an elaborate set of arguments guiding selection and presentation of results.
My records essentially cover the evolution of the NDL language until early 1977. At about that time, based on sketchier material, there were some needed developments (undoubtedly specified by others) relating to usability.
The base language was retained. But, also, the information required to establish new data types was modified and extended, to help provide system guidance for entering and viewing descriptions of expected types of application data structures (e.g., IMS data structures) to different kinds of prospective users.
For example, a "dictionary administrator" might install a new data type, e.g., a "physical data base", by a request such as:
ADD TYPE: PHYSDB(SUBSET_OF TYPE:THING
NAME_FROM ALPHA_SYMBOL
HAS_PROPERTY DBTYPE, ACCESS_METHOD..
HAS_CONTENT CTNS_SEG
HAS_VPROC VALID_PROC:PHYSDB)
(where "PROPERTY" relationships would be expected relationships that did not establish hierarchic content. Based on such a declaration, "novice" users concerned only with establishing or viewing some data base definitions would just request a display for defining a PHYSDB. The resulting display would be separated into "property" and "content" sections, and include the appropriate prompts. Or such a user might be told something like: "in order to define a new IMS physical data base you enter the following command, filling in the specified information":
ADD PHYSDB: databasename (DBTYPE dbtype
ACCESS_METHOD access_method_name
CTNS_SEG segname, segname...)
More knowledgeable users would be able to use the full language, and "dictionary administrators" would create new data types, authorize users, etc.
As outlined earlier in this chapter, there were eventually several simultaneous IBM-related efforts concerned with a data dictionary: the Dictionary Engine, NDL, and a customer effort to build an IMS-oriented prototype. The customer work was modified and extended by a separate IBM group, and released in 1976 as the "IBM DB/DC Data Dictionary" product. As far as the Dictionary Engine and NDL, it was initially assumed that the two would be conceptually compatible, so that the later-released NDL could easily cascade to the Engine base and, moreover, that users could alternate between them in accessing the same data. But as our model and language changed and evolved, it became obvious that these plans were not realistic, and a serious conflict arose.
As indicated earlier, the technical lead of the Engine project was Bob Griffith, who had strongly-held ideas (expressed in multiple internal documents) about data models, and they were different from ours. So it was understandable that he was resentful about his ideas being superseded. Thus he was not about to consider adapting the Engine to be more compatible with our model. The conflict went on for most of the autumn of 1976 and early 1977. There were exchanges of written material discussing points of incompatibility and disagreement, and at least one "task force" to try to elucidate and resolve the issues ... which were never resolved, and couldn't be.
The "issues" included conceptual mismatches and their implications for the planned release sequence, as well as semi-political arguments. The conceptual mismatches centered on the treatment of attributes. In the Engine, attributes were correlated with collections (sometimes called "categories"). They were used for name qualification, and were different from relationships. These differences made it unrealistic to consider releasing the Engine earlier than NDL, thereby subjecting users eventually to two ways of conceptualizing and referencing same data. As far as semi-political arguments, my favorite (as expressed in a combined statement of issues) was: "Dictionary should not impose a conceptual model of data base while there is still controversy in the industry regarding DB CM (data base conceptual models)". That statement, made by an representative of the Engine, was clearly disingenuous, as they had a firm intent to impose a new conceptual model as soon as it could be managed.
And then the Engine Group distributed a document about their interface, including examples of how people would add information about an IMS physical data base. Following that, we presented our model and language, and included direct comparisons of how equivalent information would be entered using NDL. And it was no contest. The NDL version was not only much shorter, but it was generally agreed that it was considerably more attractive and self-explanatory. So we scored a victory, of sorts. But we also showed how the same function would be expressed by the already-released IMS-oriented product. The latter expression of the same function was also reasonably short and did not look terribly complicated.... because it was entirely tailored to the subject matter, so many aspects were implicit. And some may have noticed....
Whatever the reason, our "victory" was short-lived. Shortly thereafter, upper management began to reevaluate much of the west coast data base work, including the dictionary projects. As a result, when the dust settled, the surviving dictionary work was directed to building new versions of the DB/DC product. See [DBDC_DICT] for some details of those versions. Separate dictionary software, in the 1980s, was eventually produced for the DB2 relational database, both by IBM and other suppliers.
I don't recall exactly when the NDL and Engine projects were discontinued, because at the time I was in the midst of relocating to Los Angeles. The long planned move from our Palo Alto office to the new "Santa Teresa Laboratory" in the far south of San Jose was about to take place, and people for whom the move would imply a very long commute were free to seek a transfer to another IBM location (with moving costs paid for by IBM). Well, I would have had a long commute, and I had heard that the IBM Los Angeles Scientific Center (LASC) was doing some work related to my interests. Also, LASC was an applied research organization, and I had enjoyed the research-like spirit in which the NDL work actually took place. So I contacted Los Angeles and shortly thereafter accepted a position there. And after getting settled, embarked on the definition of a full high-level programming language intended for a variety of data-related uses. It borrowed some ideas from our NDL work, but as a language was quite different.
I know only a little about what the people involved in the dictionary did afterwards. Bill Kent remained at IBM for some years, and then moved to Hewlett-Packard, where he focused on research and writing in the area of object-oriented data bases. Bob Griffith moved to an ASDD (Advanced Systems Development Division) facility where he continued work on his data model. Juanita Mah had become involved in the DB/DC Dictionary product somewhat earlier, continued that involvement through later releases, and went on to many responsible senior positions in IBM.
Note: It is important for me to mention that Juanita recently helped me to unscramble the organizational aspects of IBM dictionary work of the time (although, of course, any errors are mine). This was possible because she was actually familiar with all of the simultaneous dictionary projects, as well as with follow-ons; she worked not only on the original FS/ESPS dictionary project, and on the NDL project, but she was also assigned at one point to evaluate the customer-developed dictionary, and continued that involvement with its IBM product successors.
Finally (and briefly) about what happened in the area of data models like ours. Models based on essential facts, while not immediately successful, have in the early 21st century grown in popularity, because of aspects consistent with contemporary technology. For one thing, the partitioning of information into individual facts allows for (when suitable) the distribution of a database, and its gradual expansion, across the web. An important standardized version of such a distributed data model is RDF [RDF_1], which has a number of associated accessing languages.
Another aspect of such models that has increased their popularity is their consistency with contemporary display capabilities. Data collections can be depicted as networks of items, with relationships forming the links, to build connected graphs of arbitrary size, and operations on the displays permit the exploration of various paths through the graphs. Some of these data collections can be quite informal, in that they may not require the predefinition of data types, but, rather, are formed by extracting data from text as it is encountered. At any rate, however defined, collected, and portrayed, these "essential fact" data bases are sometimes called "graph data bases", and sometimes, "knowledge graphs".
And both before and alongside these developments has been the evolution of languages intended for populating formal knowledge bases. As contrasted with traditional data bases, where all facts are assumed to be "true", knowledge bases contain explicit predications, with forms equivalent to:
<existence operator> (WHERE <predicate1>) <predicate2>
The existence operators (like FOR ALL ?v, THERE EXISTS ?v) along with the first predicates (predicate1) delimit the subjects of interest, and predicate 2 states the claim being made about the subjects. (It must be stressed that there are many, many, forms of expressing such predications.) Well-known logical languages have several flavors and standards, like OWL [OWL_1] related to RDF, and CommonLogic [COMMON], and some are very complex and detailed. The languages also tend to provide forms for "ontologies", usually understood as classification hierarchies.
Finally, with respect to more general data models and data bases, the best short historical account I've found is in fact the Wikipedia entry for "Database" [WIKIDATA], and its listed sources and references.